Just-Dub-It
Video Dubbing via Joint Audio-Visual Diffusion
A joint audio-visual model is all you need for video dubbing.
* Equal contribution · † Work done during visit at Tel Aviv University and internship at Lightricks
SIGGRAPH 2026



JUST-DUB-IT maintains speaker identity and precise lip synchronization across diverse target language,
while demonstrating robustness to complex motion and real-world dynamics.
Better than state-of-the-art
LTX2.3 achieves superior voice preservation, lip synchronization, and naturalness comparied with LatentSync, X-Dub and HeyGen that rely on external voice-cloning tools (i.e. ElevenLabs in the follow examples).
Wedding Speech (French)

Source

LTX2.3 (Ours)

LatentSync

X-Dub

HeyGen
Watchmaker Bench (French)

Source

LTX2.3 (Ours)

LatentSync

X-Dub

HeyGen
Car Race (Spanish)

Source

LTX2.3 (Ours)

LatentSync

X-Dub

HeyGen
Boxer Corner (German)

Source

LTX2.3 (Ours)
LatentSync

X-Dub

HeyGen
More Results
(Click on the bottom-right button on each cell to view the generated/original video)






JUST-DUB-IT achieves high fidelity and robust synchronization across diverse scenes.
Abstract
Audio-Visual Foundation Models, which are pretrained to jointly generate sound and visual content, have recently shown an unprecedented ability to model multi-modal generation and editing, opening new opportunities for downstream tasks. Among these tasks, video dubbing could greatly benefit from such priors, yet most existing solutions still rely on complex, task-specific pipelines that struggle in real-world settings.
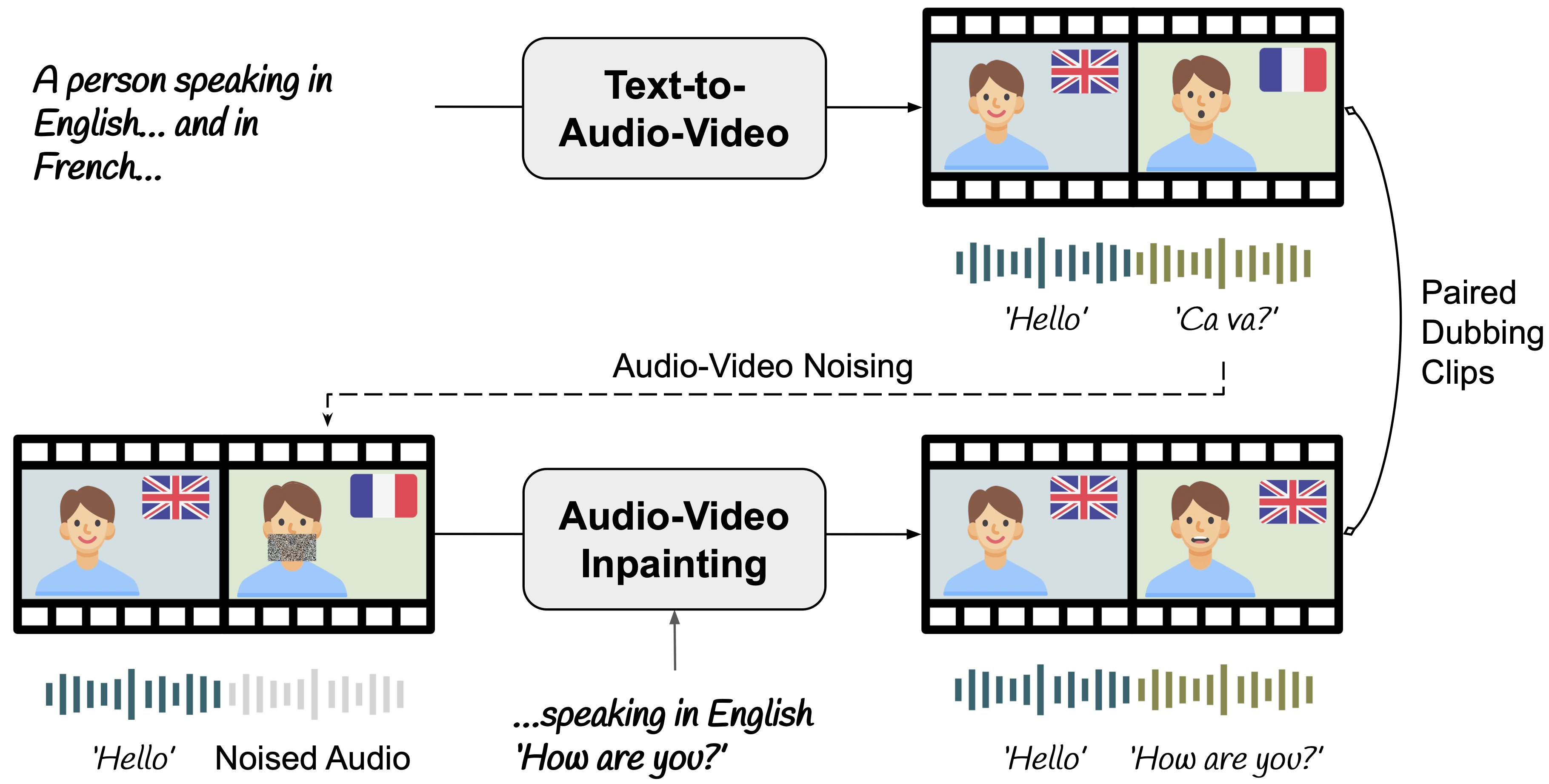
In this work, we introduce a single-model approach that adapts a foundational audio-video diffusion model for video-to-video dubbing via a lightweight LoRA. The LoRA enables the model to condition on an input audio-video while jointly generating translated audio and synchronized facial motion. To train this LoRA, we leverage the generative model itself to synthesize paired multilingual videos of the same speaker. Specifically, we generate multilingual videos with language switches within a single clip, and then inpaint the face and audio in each half to match the language of the other half.
By leveraging the rich generative prior of the audio-visual model, our approach preserves speaker identity and lip synchronization while remaining robust to complex motion and real-world dynamics. We demonstrate that our approach produces high-quality dubbed videos with improved visual fidelity, lip synchronization, and robustness compared to existing dubbing pipelines.
Method
Synthetic Data Pipeline
- · Language-Switching: Establishing ground-truth identity references via natural bilingual transitions.
- · Counterfactual Inpainting: Generating perfect multilingual pairs with identical pose/background.
- · Latent-Aware Masking: Eliminating motion leakage by computing the effective receptive field in latent space.
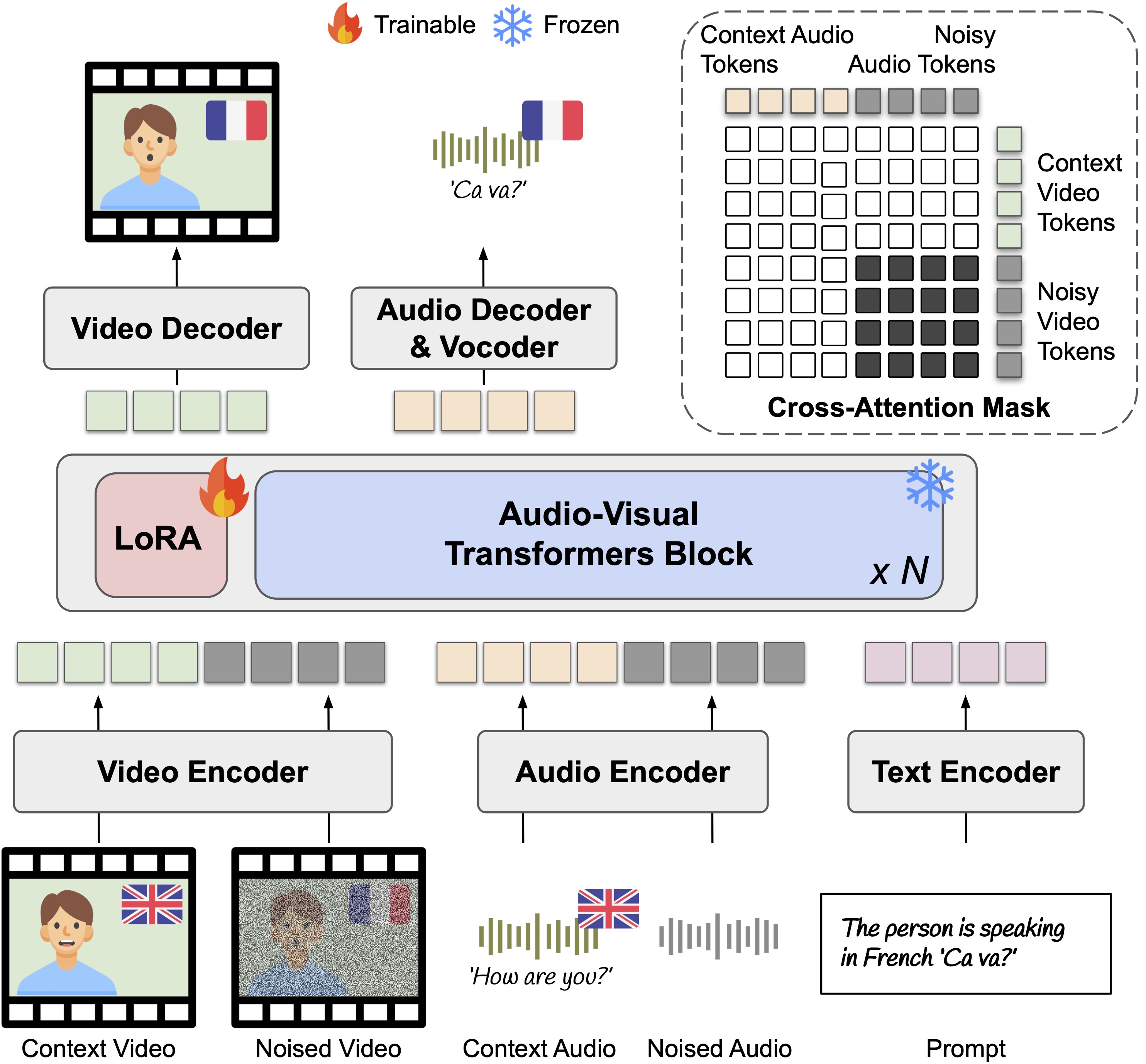
In-Context LoRA Training
- · Structural Anchoring: Leveraging source latents as anchors for context-aware completion.
- · Isolated Cross-Attention: Structured bias (Matrix M) to prevent cross-modal signal leakage.
- · Unified Signal Flow: Adapting joint audio-visual priors via efficient, lightweight LoRA adapters.
Citation
If you find this work useful, please cite our paper:
@misc{chen2026justdubitvideodubbingjoint,
title={JUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion},
author={Anthony Chen and Naomi Ken Korem and Gal Zeevi and Tavi Halperin and Matan Ben Yosef and Urska Jelercic and Ofir Bibi and Or Patashnik and Daniel Cohen-Or},
year={2026},
eprint={2601.22143},
archivePrefix={arXiv},
primaryClass={cs.GR},
url={https://arxiv.org/abs/2601.22143},
}